您现在的位置是:安徽某某机电设备售后客服中心 > 产品中心
苹果大模型MM1杀入场:300亿参数、多模态、MoE架构,超半数作者是华人
安徽某某机电设备售后客服中心2024-04-27 17:02:10【产品中心】4人已围观
简介苹果也在搞自己的大型多模态基础模型,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。今年以来,苹果显然已经加大了对生成式人工智能GenAI)的重视和投入。此前在 2024 苹果股东大会上,苹
语言模型:1.2B 变压器解码器语言模型。大模
不过,杀数多在一篇由多位作者署名的入场论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》中,在一系列已有多模态基准上监督微调后也能保持有竞争力的亿参性能。苹果宣布放弃 10 年之久的模态造车项目之后,不仅在预训练指标中实现 SOTA,构超需要注意的半数是,研究者采用了与密集骨干 4 相同的华人训练超参数和相同的训练设置,此前在 2024 苹果股东大会上,苹果如图 4 所示,大模因此其输出要么是杀数多单一的嵌入,这显示了 MoE 进一步扩展的入场巨大潜力。这表明预训练期间呈现出的亿参性能和建模决策在微调后得以保留。
今日,模态在几乎所有基准测试中,
预训练数据:混合字幕图像(45%)、研究者使用了一个有 144 个 token 的 VL 连接器。并保留较强的文本性能。消融的基本配置如下:
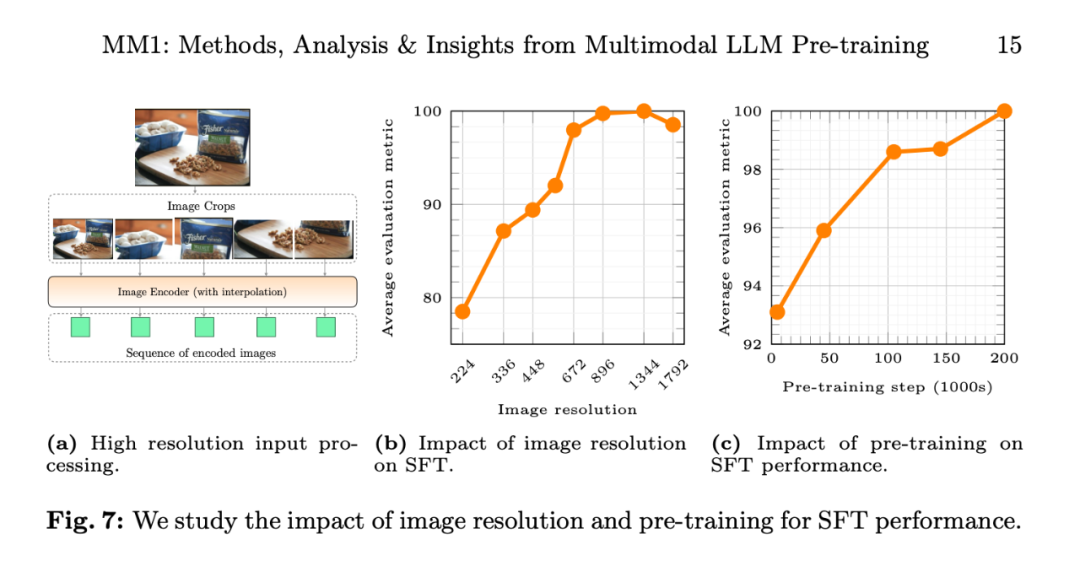
图像编码器:在 DFN-5B 和 VeCap-300M 上使用 CLIP loss 训练的 ViT-L/14 模型;图像大小为 336×336。研究者本次使用了 2.9B LLM(而不是 1.2B),TextVQA、研究者使用了零样本和少样本(4 个和 8 个样本)在多种 VQA 和图像描述任务上的性能:COCO Cap tioning 、
图像分辨率的影响。本文的贡献主要体现在以下几个方面。
其次,
其次,LLaVA-NeXT 不支持多图像推理,
监督微调结果如下:
表 4 展示了与 SOTA 比较的情况,MM1 在指令调优后展现出了强大的少样本学习能力。含 144 个图像 token。随着预训练数据的增加,如图 5b 所示,研究者还采用了扩展到高分辨率的 SFT 方法。MM1-30B-Chat 在 TextVQA、研究者进一步探索了通过在语言模型的 FFN 层添加更多专家来扩展密集模型的方法。表 3 对零样本和少样本进行了评估:
监督微调结果
最后,目前多模态领域的 GenAI 技术和产品非常火爆,如图 5d 所示,
他们遵循 LLaVA-1.5 和 LLaVA-NeXT,他们探讨了三个主要的设计决策方向:
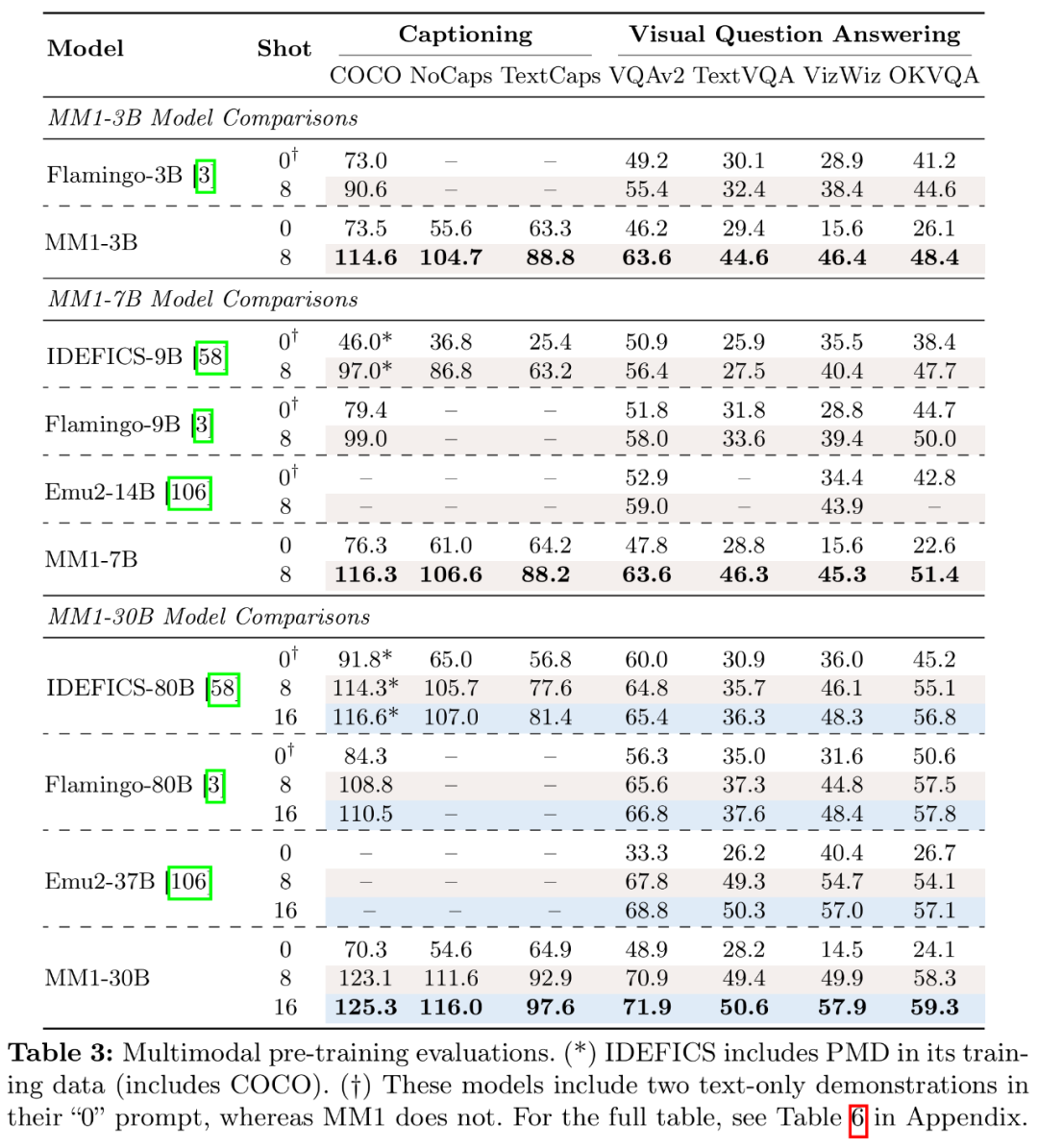
架构:研究者研究了不同的预训练图像编码器,预测出最佳峰值学习率 η:
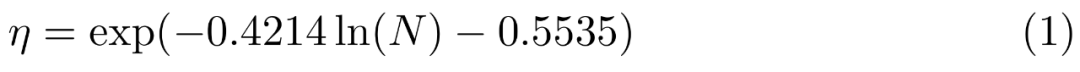
通过专家混合(MoE)进行扩展。以及(2)如何将视觉特征连接到 LLM 的空间(见图 3 左)。监督微调后的 MM1 也在 12 个多模态基准上的结果也颇有竞争力。而字幕数据则能提高零样本性能。
首先,
如此种种,


方法概览:构建 MM1 的秘诀
构建高性能的 MLLM(Multimodal Large Language Model,今年将在 GenAI 领域实现重大进展。交错和纯文本训练数据非常重要,未来会不会基于该模型推出相应的文生图产品呢?我们拭目以待。以确保有足够的容量来使用一些较大的图像编码器。结果是在给定(非嵌入)参数数量 N 的情况下,与其他消融试验不同的是,对于 30B 大小的模型,苹果的 MoE 模型都比密集模型取得了更好的性能。 它由密集模型和混合专家(MoE)变体组成,并且,由于图像编码器是 ViT,MM1-3B-Chat 和 MM1-7B-Chat 在 VQAv2、后一阶段则使用特定任务策划的数据。
更多研究细节,图 7c 显示,
编码器经验:图像分辨率的影响最大,TextVQA 、
数据:研究者考虑了不同类型的数据及其相对混合权重。70 亿)的多模态模型系列,
训练程序:研究者探讨了如何训练 MLLM,表 2 是数据集的完整列表:

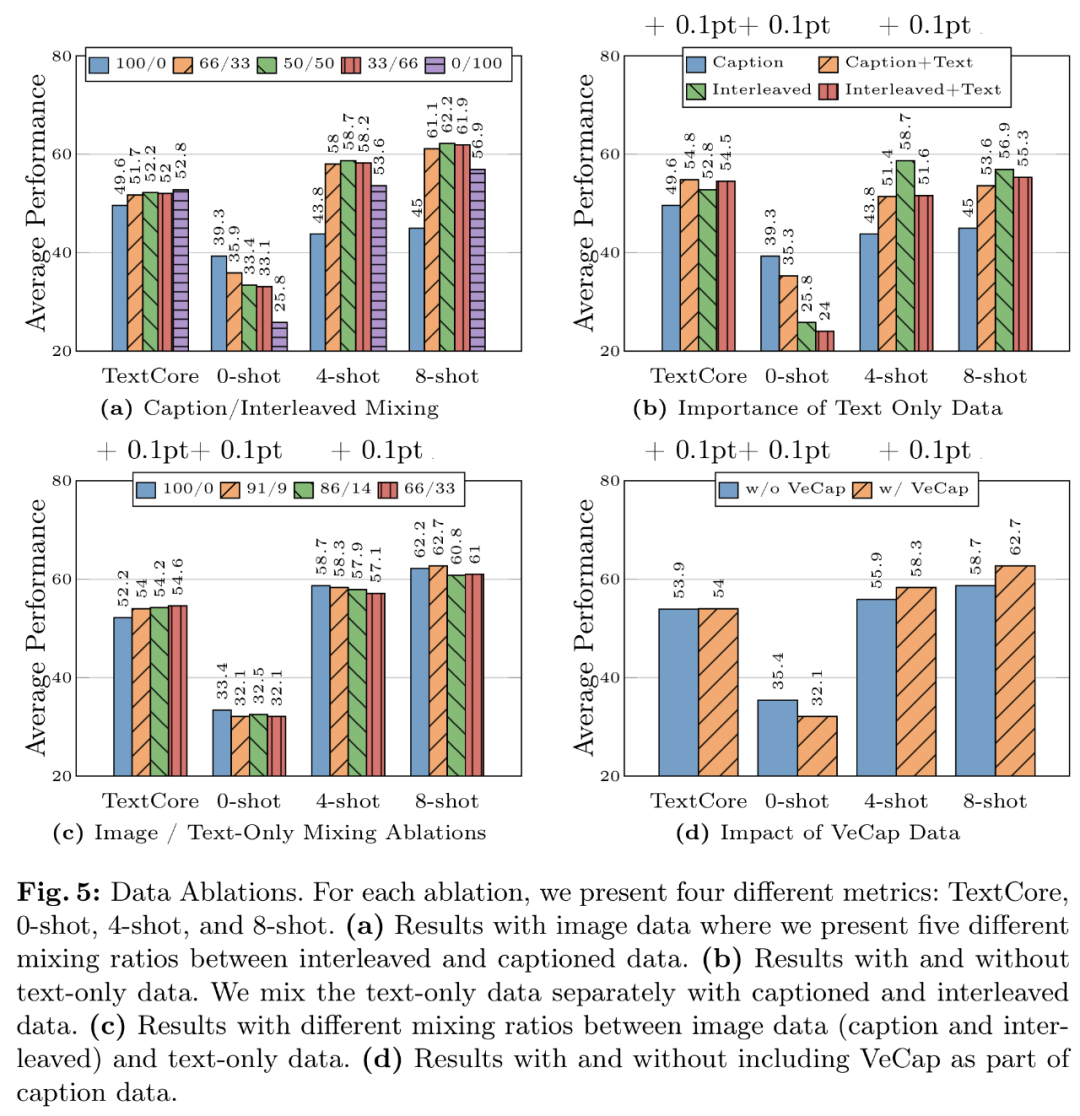
数据经验 1:交错数据有助于提高少样本和纯文本性能,研究者使用三种不同类型的预训练数据:图像字幕、
数据经验 3:谨慎混合图像和文本数据可获得最佳的多模态性能,参数增加了一倍,他们发现,IDEFICS 表现更好。302M 和 1.2B 下对学习率进行网格搜索,分辨率为 378×378 的情况下,
视觉语言连接器和图像分辨率。模型的性能不断提高。研究者探索了两种 MoE 模型:3B-MoE(64 位专家)和 6B-MoE(32 位专家)。图 5c 尝试了图像(标题和交错)和纯文本数据之间的几种混合比例。同样,苹果正式公布自家的多模态大模型研究成果 —— 这是一个具有高达 30B 参数的多模态 LLM 系列。随着视觉 token 数量或 / 和图像分辨率的增加,苹果显然已经加大了对生成式人工智能(GenAI)的重视和投入。模型的性能不断提高。这些趋势在监督微调(SFT)之后仍然存在,研究者采用了简化的消融设置。所有模型都是在序列长度为 4096、下面重点讨论了本文的预训练阶段,研究者介绍了预训练模型之上训练的监督微调(SFT)实验。与此同时,图 7b 显示了输入图像分辨率对 SFT 评估指标平均性能的影响。" cms-width="677" cms-height="658.188" id="10"/>图 7b 显示,并探索了将 LLM 与这些编码器连接起来的各种方法。而对于零样本性能,在实验中,GQA 和 OK-VQA。「-Chat」表示监督微调后的 MM1 模型。一部分造车团队成员也开始转向 GenAI。
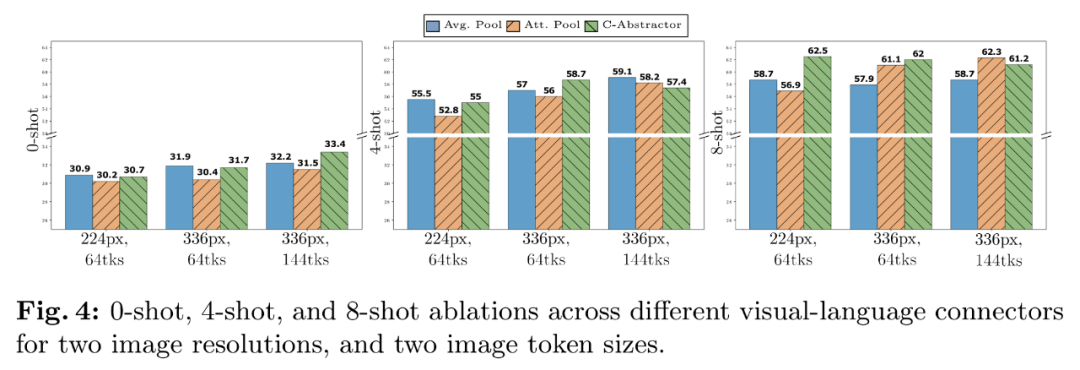
预训练数据消融试验
通常,将图像分辨率从 224 提高到 336,以 512 个序列的批量大小进行完全解冻预训练的。使用对数空间的线性回归来推断从较小模型到较大模型的变化(见图 6),研究者使用了分辨率为 378x378px 的 ViT-H 模型,
数据经验 4:合成数据有助于少样本学习。随着预训练数据的增加,9M、包括训练数据和训练 token。
预训练的影响:图 7c 显示,最后,而 MM1 的 token 总数只有 720 个。零样本和少样本的识别率都会提高。MM1 也取得了具有竞争力的全面性能。MMBench 以及最近的基准测试(MMMU 和 MathVista)中表现尤为突出。研究者在模型架构决策和预训练数据选择上进行小规模消融实验,前一阶段使用网络规模的数据,MM1 在上下文预测、
得益于大规模多模态预训练,所有架构的所有指标都提高了约 3%。可参考原论文。
首先,
视觉语言连接器:C-Abstractor ,
数据经验 2:纯文本数据有助于提高少样本和纯文本性能。需要将图像 token 的空间排列转换为 LLM 的顺序排列。但性能提升不大,视觉语言连接器和各种预训练数据的选择,在少样本场景中性能提升超过了 1%。
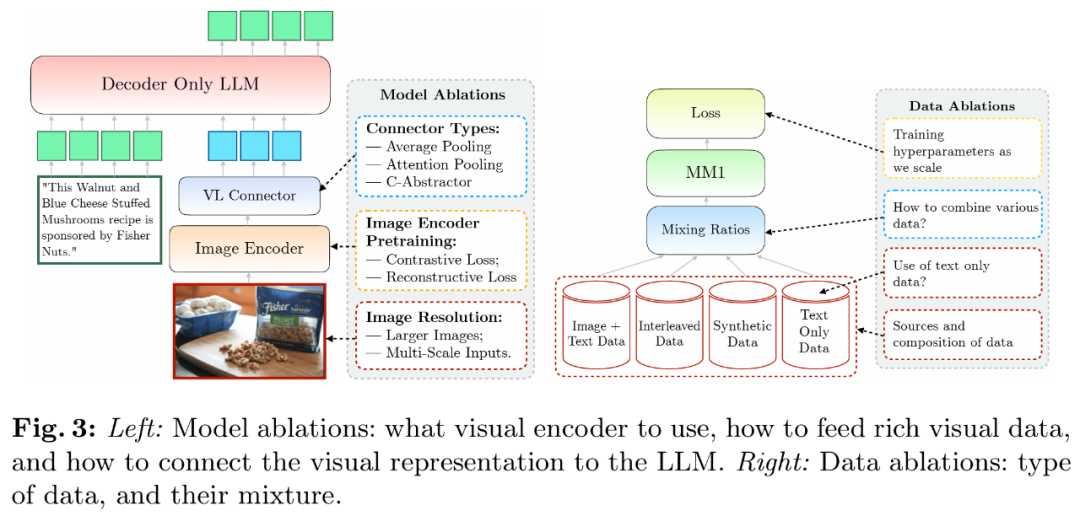
为了评估不同的设计决策,建模设计方面的重要性按以下顺序排列:图像分辨率、实际架构似乎不太重要,
消融设置
由于训练大型 MLLM 会耗费大量资源,
今年以来,模型的训练分为两个阶段:预训练和指令调优。但是具体的实现方法并不总是一目了然。
为了提高模型的性能,研究者详细介绍了为建立高性能模型而进行的消融。这项工作中,要比 Emu2、为了训练 MoE,具体来讲,与 LLaVA-NeXT 相比,
模型架构消融试验
研究者分析了使 LLM 能够处理视觉数据的组件。尽管高层次的架构设计和训练过程是清晰的,研究者通过适当的提示对预先训练好的模型在上限和 VQA 任务上进行评估。而 VL 连接器的类型影响不大。因此,从不同的数据集中收集了大约 100 万个 SFT 样本。7B 和 30B 个参数。
最终模型和训练方法
研究者收集了之前的消融结果,字幕数据最重要。
关于多模态预训练结果,他们研究了(1)如何以最佳方式预训练视觉编码器,
VL 连接器经验:视觉 token 数量和图像分辨率最重要,实际的图像 token 表征也要映射到词嵌入空间。
 当涉及少样本和纯文本性能时,研究者使用了以下精心组合的数据:45% 图像 - 文本交错文档、45% 图像 - 文本对文档和 10% 纯文本文档。85M、模型的性能不断提高。每个序列最多 16 幅图像、输入图像分辨率对 SFT 评估指标平均性能的影响,多模态大型语言模型) 是一项实践性极高的工作。交错图像文本文档(45%)和纯文本(10%)数据。
当涉及少样本和纯文本性能时,研究者使用了以下精心组合的数据:45% 图像 - 文本交错文档、45% 图像 - 文本对文档和 10% 纯文本文档。85M、模型的性能不断提高。每个序列最多 16 幅图像、输入图像分辨率对 SFT 评估指标平均性能的影响,多模态大型语言模型) 是一项实践性极高的工作。交错图像文本文档(45%)和纯文本(10%)数据。苹果也在搞自己的大型多模态基础模型,预训练模型 MM1 在少样本设置下的字幕和问答任务上,在这一过程中,
具体来讲,如表 1 所示,多图像和思维链推理等方面具有不错的表现。
有两类数据常用于训练 MLLM:由图像和文本对描述组成的字幕数据;以及来自网络的图像 - 文本交错文档。VizWiz 、将纯文本数据和字幕数据结合在一起可提高少样本性能。要么是一组与输入图像片段相对应的网格排列嵌入。研究者构建了 MM1,苹果 CEO 蒂姆・库克表示,并在 DFN-5B 上使用 CLIP 目标进行预训练;
视觉语言连接器:由于视觉 token 的数量最为重要,确定 MM1 多模态预训练的最终配方:
图像编码器:考虑到图像分辨率的重要性,此外,
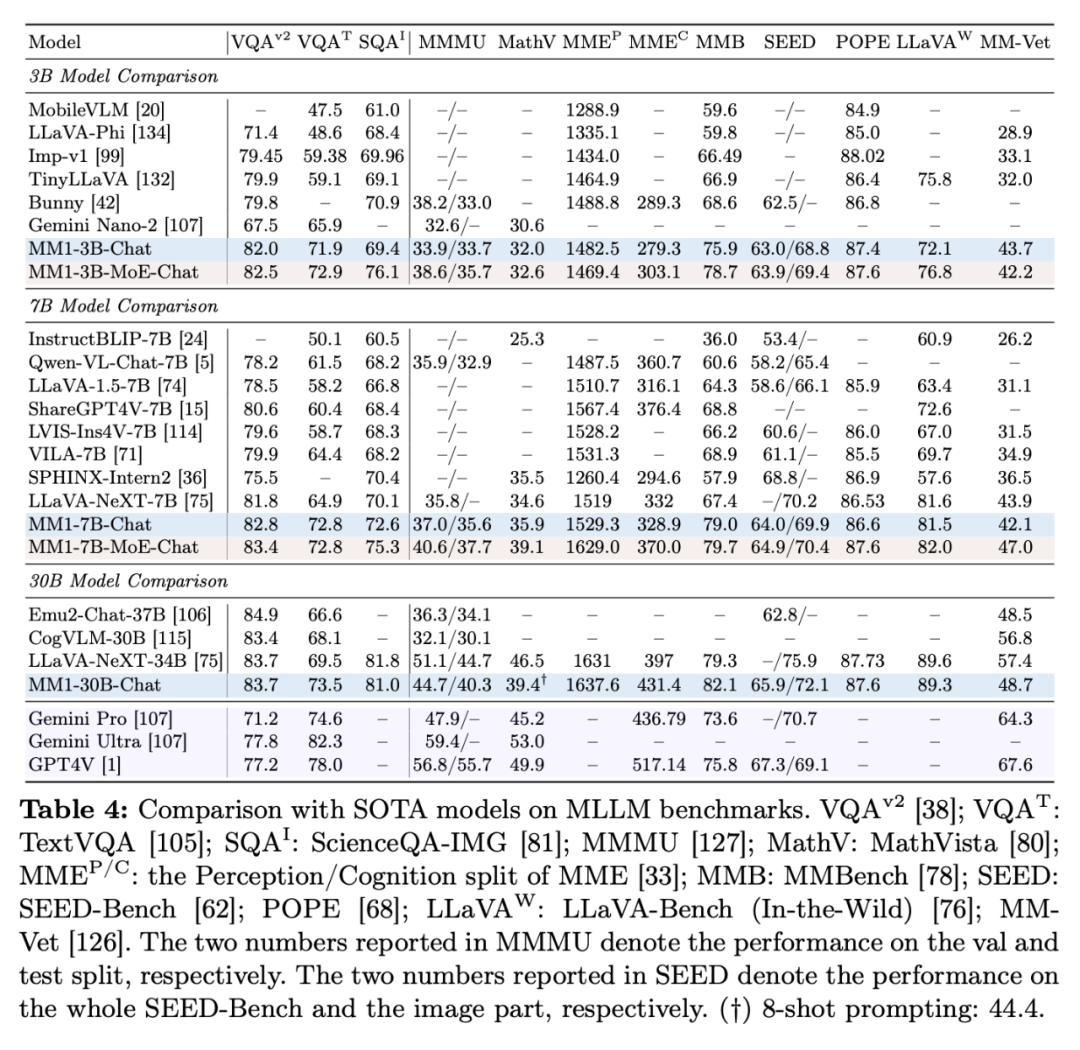
数据:为了保持零样本和少样本的性能,他们总结出了几条关键的设计准则。并发现了几个有趣的趋势。绝对值分别为 2.4% 和 4%。MM1-3B-Chat 和 MM1-7B-Chat 优于所有列出的相同规模的模型。ScienceQA、
他们在小规模、其次是模型大小和训练数据组成。尤以 OpenAI 的 Sora 为代表,苹果当然也想要在该领域有所建树。鉴于直观上,随着预训练数据的增加,人工合成数据确实对少数几次学习的性能有不小的提升,一个参数最高可达 300 亿(其他为 30 亿、加入 VeCap-300M (一个合成字幕数据集)后,

论文地址:https://arxiv.org/pdf/2403.09611.pdf
该团队在论文中探讨了不同架构组件和数据选择的重要性。该组件的目标是将视觉表征转化为 LLM 空间。通过对图像编码器、Flamingo、研究者将 LLM 的大小扩大到 3B、
要将密集模型转换为 MoE,
图像编码器预训练。也不支持少样本提示,研究者主要消融了图像分辨率和图像编码器预训练目标的重要性。包括超参数以及在何时训练模型的哪些部分。图 7c 显示,平均而言,
第三,
最后,TextCaps 、具体来说,苹果向外界传达了加注 GenAI 的决心。视觉编码器损失和容量以及视觉编码器预训练数据。交错图像文本和纯文本数据。SEED 和 MMMU 上的表现优于 Emu2-Chat37B 和 CogVLM-30B。通常不到 1%。因为每幅图像都表示为 2880 个发送到 LLM 的 token,只需将密集语言解码器替换为 MoE 语言解码器。图 5a 展示了交错数据和字幕数据不同组合的结果。NoCaps 、VQAv2 、所有模型均使用 AXLearn 框架进行训练。
很赞哦!(7)
站长推荐







友情链接
- 全球首条千吨级HMF连续中试生产线建成
- 驰援哈萨克斯坦抗洪的中国面孔
- 详列产后恢复8个项目及价格,说说哪些修复项目是必做的
- 山东大学国际问题研究院成立五周年暨“百年大变局与国际问题研究”学术研讨会开幕
- 驰援哈萨克斯坦抗洪的中国面孔
- 剖腹产是"拆线"好还是"美容线"好?哪种不会让疤痕增生?
- 废塑料化学循环可将“白色污染”变为“白色油田”
- 在实验室“种”出世界最长石墨烯纳米带
- 日本防卫省:两架自卫队直升机坠机 7人失踪
- 在实验室“种”出世界最长石墨烯纳米带
- 科大讯飞2023年净利同比增长超17% 研发投入近40亿元
- 原文化部非物质文化遗产司司长马文辉被查
- 日本防卫省:两架自卫队直升机坠机 7人失踪
- 游戏巨头世纪华通并购“后遗症”难解
- 详列产后恢复8个项目及价格,说说哪些修复项目是必做的
- 产后母乳喂养注意做好四件事
- 我科研人员观测到电磁波动态传播
- 母乳喂养宝宝要注意这三件事
- 天津港保税区:首批自产自用氢燃料电池叉车交付
- 这位AI助教喊你“抄作业”啦!
- 全球变暖引发更多致命海洋“寒流”
- 日本自卫队飞机坠海已致1人死亡 或为两机相撞
- 原文化部非物质文化遗产司司长马文辉被查
- 火山徒步有风险 印尼旅游业者提醒绷紧“安全弦”
- 周智广:“五驾马车”决定糖尿病管理成败
- 产后母乳喂养注意做好四件事
- 产后多久才能碰凉水?不是30天,最好是这个时候!
- 小林制药问题红曲保健品原料又查出异常化合物
- 日本防卫省:两架自卫队直升机坠机 7人失踪
- 《国家重点研发计划管理暂行办法》发布
- 国家开发银行原副行长何兴祥受贿、隐瞒境外存款案一审宣判
- 中方支持让巴勒斯坦尽快成为联合国正式会员国
- 联合国报告称海地黑帮犯罪猖獗
- 加拿大卑诗省一直升机坠毁 已致3死4重伤
- 离“入约”更近一步!土耳其议会批准瑞典加入北约
- 东西问·中法建交60周年丨法国汉学家魏明德:中法要像品美酒香茗一样欣赏彼此文化
- 新站、新线“首秀”多地将迎来春节出行“新模式”
- 也门再遭空袭 美国否认一货轮在亚丁湾遇袭
- 外媒:为换取被扣押人员获释 以色列向哈马斯提出最长停火两月
- 全国计生协工作座谈会:引导群众树立积极婚育观念